
Technology
Complete Round Up Of Latest Technology In Cars, From V2V To Biometric, This is all You Need To Know

Automobile industries constantly use innovative technologies. In fact, every year, the car industry tries developing some unique and innovative technologies to grab their customer’s attention.
Although a lot of products related to technology are coming up with their own strategic techniques, there is a way more on the way which is going to transform the industry of cars forever.
Here, we share some of those technologies of which you may not be aware.
1) Vehicle to Vehicle or V2V communication
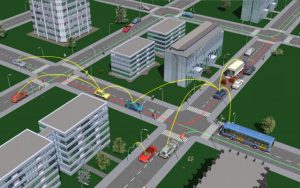
This innovation is quite helpful to prevent the possible accidents that might actually happen if your are not alert. Cars will communicate with each other and alert the drivers about the roadside hazard ahead. Simply put, V2V communication would warn the driver but not take control of the car.
V2V communications comprise of a wireless network where automobiles send messages to each other with information about what they are doing.
This V2V technology receives a signal through the other car in your direct path, then warns you about the potential accident or either brake automatically.
2) Biometric seat prototype

Well, this is something interesting. Biometric seats use health monitoring technology to detect and alert the drivers when their stress levels are too high to drive the car. This biometric seat uses data from your face, palms, combined with real information that gets collected through the car’s accelerator, clutch, brakes, throttle as well as the steering wheel to monitor your stress levels.
Simply speaking, it does a medical check to track your stress levels and lets you know if this is the right time to take a break.
3) Connected cars

A connected car is a car that is equipped with internet access. This allows the cars to share internet access with other devices both inside and outside the vehicle. A sim card will be pre-installed which can offer remote diagnostics.
Based on a survey, they reveal that by 2020, there will be over hundred and seventy million cars of this type in this world.
4) Driver override systems

With the advancement of automotive technology, vehicles actively make their decision if the driver fails to apply brakes at the time of the collision. The rapid increase of sensor technology helps vehicles to make firm decisions when the driver fails to take any action manually.
If this application becomes a permanent part of vehicles, then it could avoid many uncertain crashes on road. This application also helps the vehicle user to feel confident that they can get the vehicle in control if any abnormal situation happens. This also gives the ability to step on the break if the system malfunctions at any point.
5) Body panels to store energy

These body panels installed in cars and are designed to absorb energy from multiple means including plugging in overnight and regenerative braking, which is then stored and regenerated when needed.
This technology would contribute to the already existing electric cars which include zero emission and superior acceleration, by reducing the size of electric car batteries, eliminating the wasted energy used up in moving the extra weight in batteries.These panels are predicted to be in production soon after 2020.




UAE-based G42 has announced plans to deploy an 8 exaflop AI supercomputer in India, announced at the AI Impact Summit 2026 in Delhi. This national-scale project partners with Cerebras, MBZUAI, and India’s C-DAC, operating under full Indian data sovereignty as part of the India AI Mission.
The supercomputer boosts sovereign AI capabilities, enabling startups, researchers, academics, SMEs, and government access for tailored applications like public services and language tech. G42 India CEO Manu Jain highlighted its role in making India AI-native while prioritizing security.
This follows India-UAE tech pacts in late 2025, positioning India among global leaders in exaflop AI infrastructure amid rising demand for localized compute. Cerebras CSO Andy Hock noted it will accelerate large model training for India-specific needs.

Google has launched the Google Startup Hub Hyderabad, a major step in strengthening India’s dynamic startup ecosystem. This new initiative aims to empower entrepreneurs, innovators, and developers by giving them access to Google’s global expertise, mentoring programs, and advanced cloud technology. The hub reflects Google’s mission to fuel India’s digital transformation and promote innovation through the Google for Startups program.
Located in the heart of one of India’s top tech cities, the Google Startup Hub in Hyderabad will host mentorship sessions, training workshops, and networking events designed for early-stage startups. Founders will receive Google Cloud credits, expert guidance in AI, product development, and business scaling, and opportunities to collaborate with Google’s global mentors and investors. This ecosystem aims to help Indian startups grow faster and compete globally.
With Hyderabad already home to tech giants like Google, Microsoft, and Amazon, the launch of the Google Startup Hub Hyderabad further cements the city’s position as a leading innovation and technology hub in India. Backed by a strong talent pool and robust infrastructure, this hub is set to become a growth engine for next-generation startups, driving innovation from India to global markets.

- Jio Platforms has launched JioPC, a cloud-based virtual desktop service that transforms any television connected to a Jio Set Top Box into a fully functional computer.
- Users simply connect a keyboard and mouse to access a desktop-like environment, complete with web browsing, productivity tools, and educational apps—all without needing a physical PC or extra hardware.
- The service is device-agnostic and works with all consumer PC brands, making advanced computing accessible and affordable for millions across India.
JioPC is designed to support a wide range of activities, from professional work to online learning and creative projects. By leveraging Jio’s robust cloud infrastructure, users can run even compute-intensive AI applications directly from their TV screens. The platform also ensures data security and reliability, as all files and settings are safely stored in the cloud, protecting users from data loss even if their device is reset or replaced.
With JioPC, Jio aims to democratize digital access and bring high-performance computing to Indian households at a fraction of the traditional cost. The service supports popular productivity suites like LibreOffice and Microsoft Office online, and Jio is offering a free trial to encourage users to experience the benefits firsthand. This innovative move is set to reshape how people in India work, learn, and connect in the digital age.





